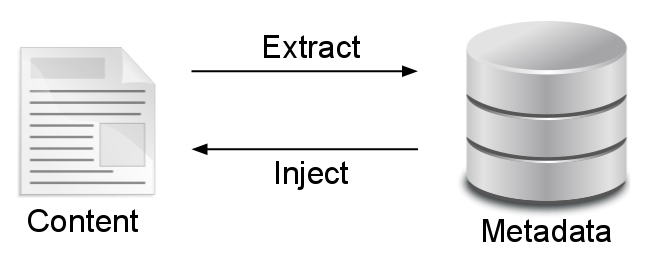
In Componize, and depending on the processing rules that are defined for a specific document or document type, metadata may be extracted from the content or injected back into the content.
Under the hood, Componize uses an RDF graph as a temporary, generic way to model the information that gets transferred from the content to the metadata storage and back.
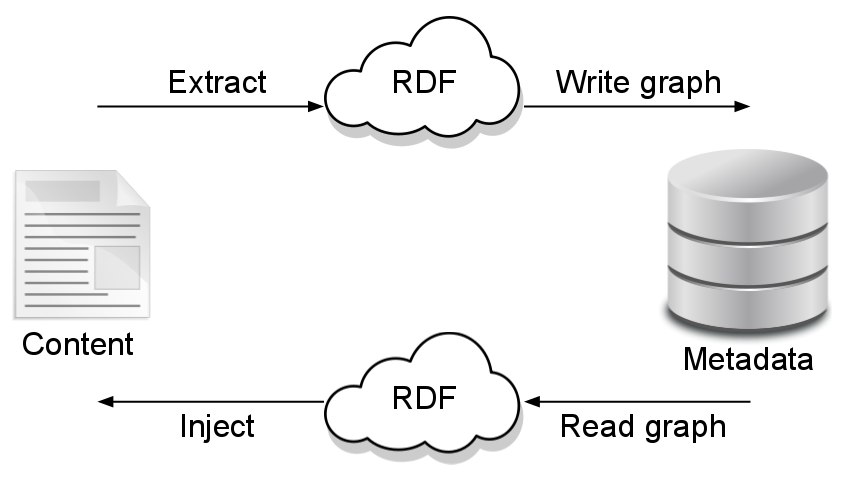
A component that extracts information from the content and maps it to RDF triples is called a Metadata extractor. The most common Metadata extractoris the one that uses XPath expressions to extract information. There are additional extractors, such as one that creates triples according to the type of the document (DTD or XSD).
A component that injects information into the content (by rewriting it) according to a given RDF graph is called Metadata interceptor. The most common Metadata interceptoris the one that uses XPath expressions to update content.
A component that maps the extracted RDF information to the metadata store is called a graph writer. By default, Componize will try and map triples implicitly when the subject is a node reference in Alfresco and the predicate is a known property from the content model. In such a case, Componize will try and set the property value according to the object of the triple. When the predicate is a know aspect from the content model, Componize will try and add the related aspect. Further customization may be applied, for example to explicitly map a given predicate to another aspect.
A component that maps the information from the metadata store to a set of triples in an RDF graph is called a graph reader.